
Data Engineering
Data Flow Pillars
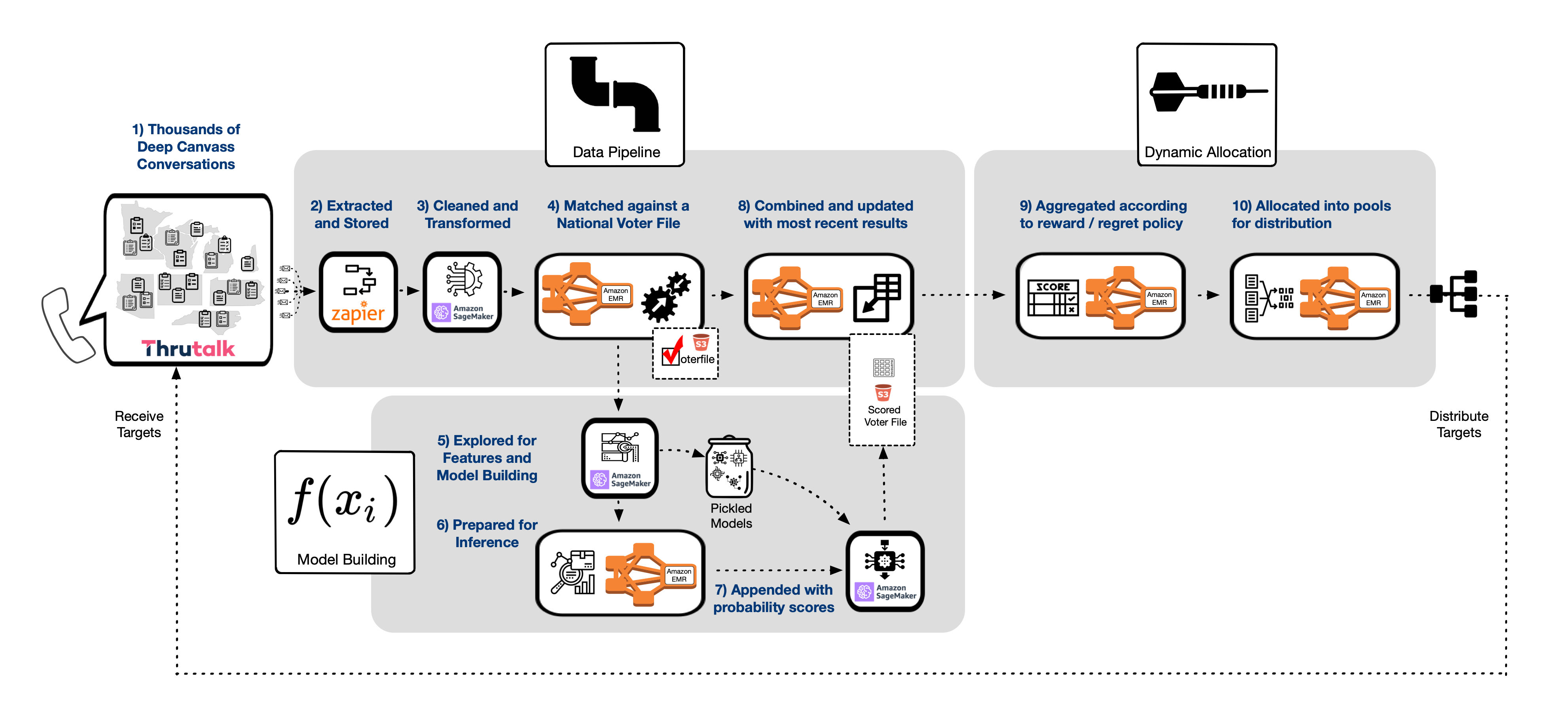
To build our solution we designed three main data flow pillars. First we have a data ingestion pipeline. In this part of the process we clean, dedupe and homogenize the raw data into a consistent format. Then we match records to a voter file using a custom scoring algorithm. Finally, we deliver clean, feature-enriched data suitable for EDA, model building and other downstream tasks.
In the model building portion of the pipeline we performed data analysis and implemented models described by our model strategies. We also leveraged this part of the pipeline to construct a pre-scored 40M record set that includes the probabilities and binary outcomes from our best models.
The third and final process is our allocation and distribution mechanism described by DARTS that assigns targets based on recent online updates. This part of the process leverages the same pipeline infrastructure we use for ingestion, but instead of delivering files for modeling, we update our pre-scored file with daily information on canvassing results and other statistics needed for target pool allocations.
Sources and Components
Our source data is housed in two primary platforms: Thrutalk and Civis. Much of our source data is pushed to us through Redshift queries and jobs that are scheduled on these platforms. The files are transferred through transient S3 buckets to our own staging areas using automation scripts developed in Zapier. The heavy lifting portion of our pipeline utilizes Amazon EMR. SageMaker is used for EDA, feature engineering and model building.